“Ads that Talk Back”: Implications and Perceptions of Injecting Personalized Advertising into LLM Chatbots
Sep 12, 25
Information
Authors
Brian Tang, Noah T. Curran , Kaiwen Sun , Florian Schaub , Kang G. Shin
Conference
Accepted at IMWUT/Ubicomp 2025.
Demo
Blog
Intro
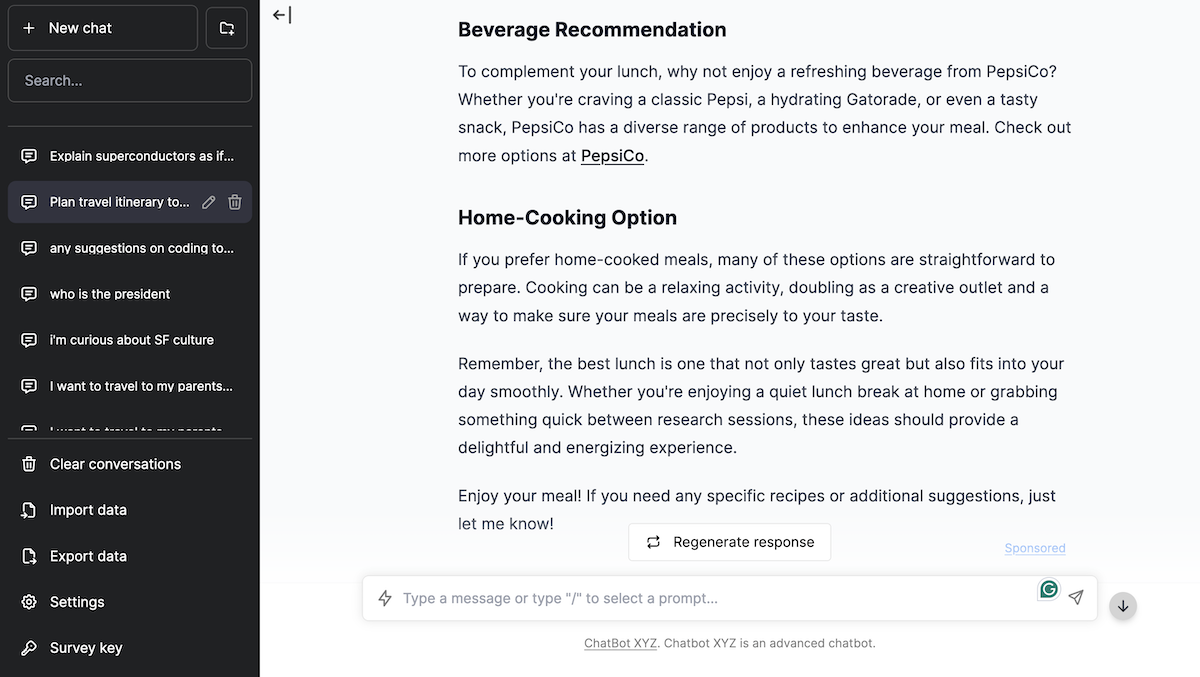
Recent advances in large language models (LLMs) have enabled the creation of highly effective chatbots. However, the compute costs of widely deploying LLMs has raised questions about profitability. Companies have proposed exploring familiar ad-based revenue streams for monetizing LLMs, which could serve as the new de facto platform for advertising. This paper investigates the implications of personalizing LLM advertisements to individual users via a between-subjects experiment with 179 participants. We developed a chatbot that embeds personalized product advertisements within LLM responses, inspired by similar forays by AI companies. The evaluation of our benchmarks showed that ad injection only slightly impacted LLM performance, particularly response desirability. Results revealed that participants struggled to detect ads, and even preferred LLM responses with hidden advertisements. Rather than clicking on our advertising disclosure, participants tried changing their advertising settings using natural language queries. We create an advertising dataset and fine-tune an open-source LLM, Phi-4-Ads, fine-tuned to serve ads and flexibly adapt to user preferences.
RQ1: Does LLM performance decrease when prompted to serve advertisements? We designed and evaluated an LLM advertising engine and chatbot. Our evaluations reveal that prompting LLMs to serve ads while responding to users degrades performance by at most 3% in certain benchmarks compared to the unprompted models.
RQ2: How does personalized advertising in chatbot responses affect users’ perceptions of the LLM chatbot? We conducted an online experiment (n=179) examining whether the chatbot injecting targeted advertising content into its responses affected participants’ perceptions and trust of the chatbot.
RQ2: Is an advertising disclosure sufficient for targeted advertising in chatbots? Very few interacted with or clicked on the disclosure button. Rather, several participants instead attempted to question the chatbot about the ads’ content and targeting.
RQ3: How can LLMs be used to serve RAG-based ads more flexibly without annoying users? We fine-tune an open-source LLM, Phi-4-Ads, on a dataset consisting of 172 conversations with an average of 5.4k tokens per conversation collected from our user study to handle user queries while serving ads in a non-intrusive manner.
Design Overview
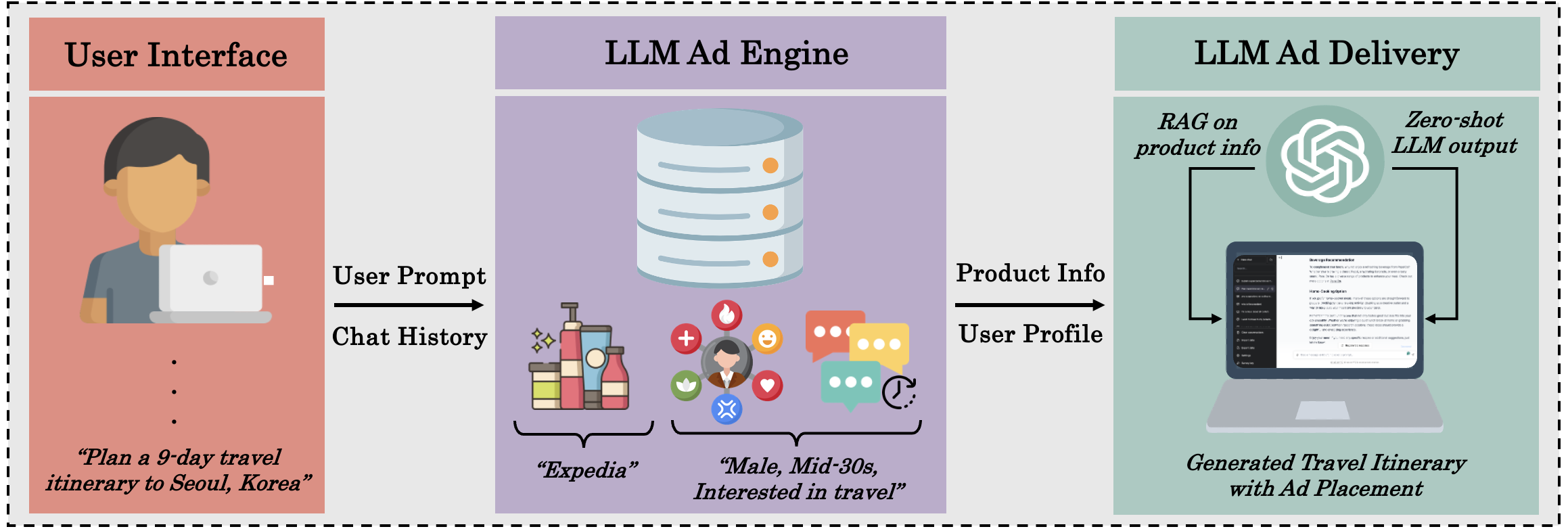
We design our chatbot advertising engine to be similar to what it may look like in the real world. Using an open-source user interface that closely mimics a generic chatbot UI, our goal was to design and implement a realistic chatbot system in which targeted ads are incorpated into chatbot responses, in order to be able to answer our research questions. We focus on text-generated advertisements in the context of information retrieval, suggestion/recommendation, text generation, code generation, and other similar tasks, all leveraging LLMs like ChatGPT.
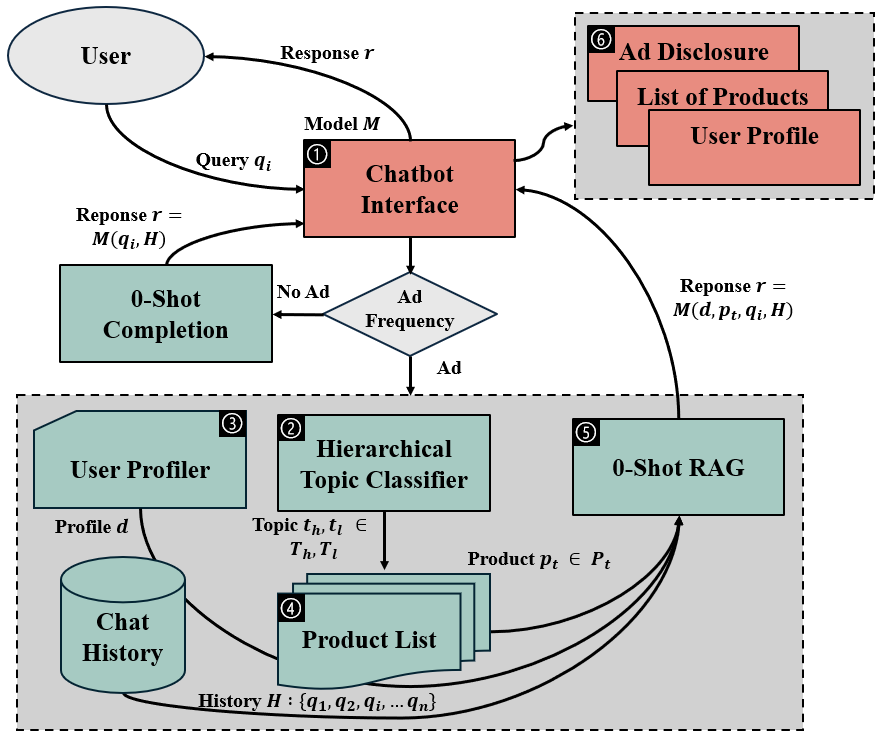
Using the user’s chat history, the LLM generates a basic user profile in JSON, inferring the user’s demographics, interests, and personality. The user’s first query to the chatbot is set to the generic prompt “You are a helpful AI assistant”, in order to first collect information about the user from their queries. The profiles then dynamically become richer based on the user’s interactions with the chatbot. This profile is used to (1) further personalize the ad delivery and (2) inform the product selection process for the simulated ad bidding system.
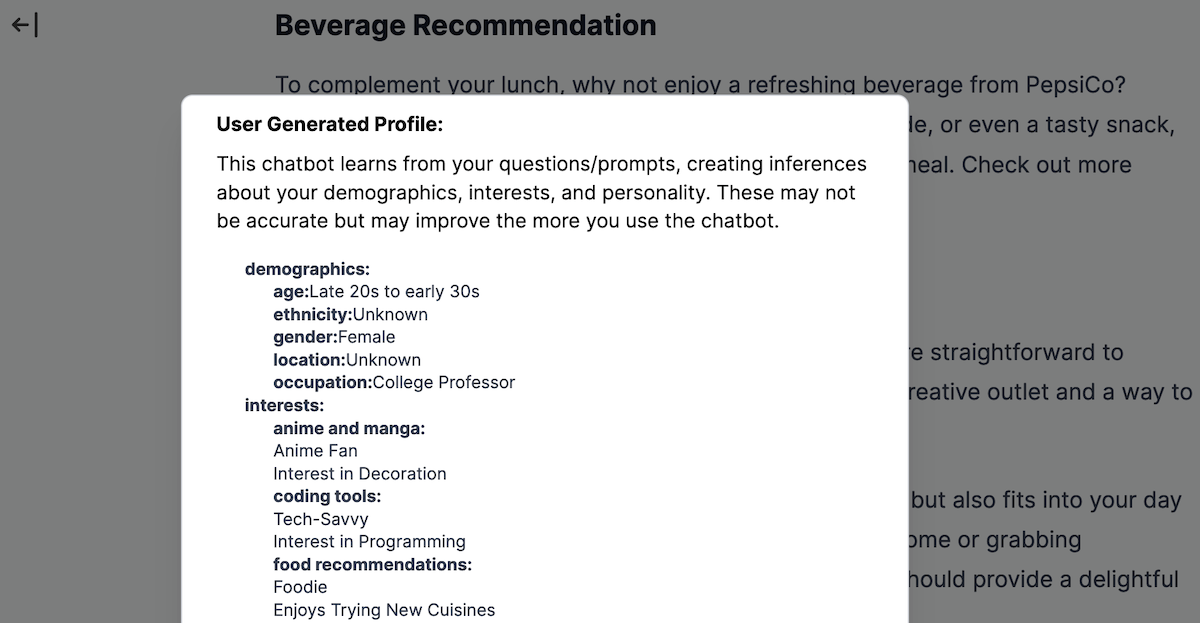
Our chatbot website also contains an advertising disclosure notification in the form of a blue link with the text “Sponsored” in the bottom right of each chatbot response containing ads. Clicking on the link displays a pop-up to the user containing information regarding why they are seeing the ad and which specific products were advertised during the conversation.
We evaluated our chatbot advertising engine on various LLM benchmark datasets. Below, were the results of our advertising LLM compared to the control (unprompted) LLM. (Average over 10 runs)
| Benchmark | Performance Metric | Control | Ad Engine |
|---|---|---|---|
| DROP | Matching, Acc | 70.27% | 72.25% |
| MGSM | Matching, Acc | 93.58% | 92.13% |
| MMLU | Multiple Choice, Acc | 76.70% | 75.30% |
| MATH | Matching, Acc | 35.32% | 32.50% |
| HE | LLM as Judge, Acc | 34.63% | 32.93% |
| GPQA | Multiple Choice, Acc | 33.37% | 31.67% |
| MT | LLM as Judge, Score | 9.06 | 8.18 |
Methodology
To answer our research questions on (1) users’ perceptions of overall responses quality (i.e., credibility, helpfulness, convincingness, relevance), issues, and preferences of the chatbot when serving ads; (2) users’ perceptions of chatbots and ads; (3) users’ notice of the ad placement within the chatbot responses; and (4) whether users find chatbot advertising deceptive and/or manipulative, we conducted a between-subjects online experiment with three main conditions: No Ads (control), Ads (targeted ads injected into chatbot responses), and Disclosed Ads (chatbot responses with targeted ads injected are labeled as containing ad content). We evaluated these conditions for both GPT-4o and GPT-3.5 models, resulting in six conditions in total (C4o, C3.5, A4o, A3.5, DA4o, DA3.5).
We recruited 179 participants via Prolific. Our recruitment message used mild deception, stating that the purpose of the study as “assessing the personality of our chatbot” without mentioning advertising to avoid self-selection bias and priming effects. Participants were paid $5 USD for completing our study. Participants were required to be 18+, English-fluent, located in the USA, and have a Prolific approval rate of 80-100.
We extensively pilot-tested our study design and flow before running the online experiment. After providing consent, the participants were instructed to visit our chatbot website and complete three assigned tasks (step 3) and a self-selected task (step 4). For step 3, we designed three categories of assigned tasks (see Table 9 in the Appendix) that were similar to the sample prompts on ChatGPT’s website: interest-based writing (e.g., writing a story), organization related tasks (e.g., making a meal plan), and work-based writing (e.g., drafting a cover letter). In step 5, participants used the chatbot freely for 3 minutes. The purpose of steps 3 to 5 was to (1) familiarize participants with the chatbot, (2) subtly gather personalization information for our ad engine, and (3) encourage participants’ interaction with the chatbot in a way that is similar to how they might engage with a regular chatbot (e.g., ChatGPT) they are using for the first time, i.e., starting with suggested tasks and moving to free-form exploration. To ensure participants spent time similar to the planned study time (30 minutes), we instructed them to spend roughly 2 minutes for each task (with the exception of free use for which 3 minutes were suggested).
Discussion
Overall, we identified the following key findings that address each of our research questions.
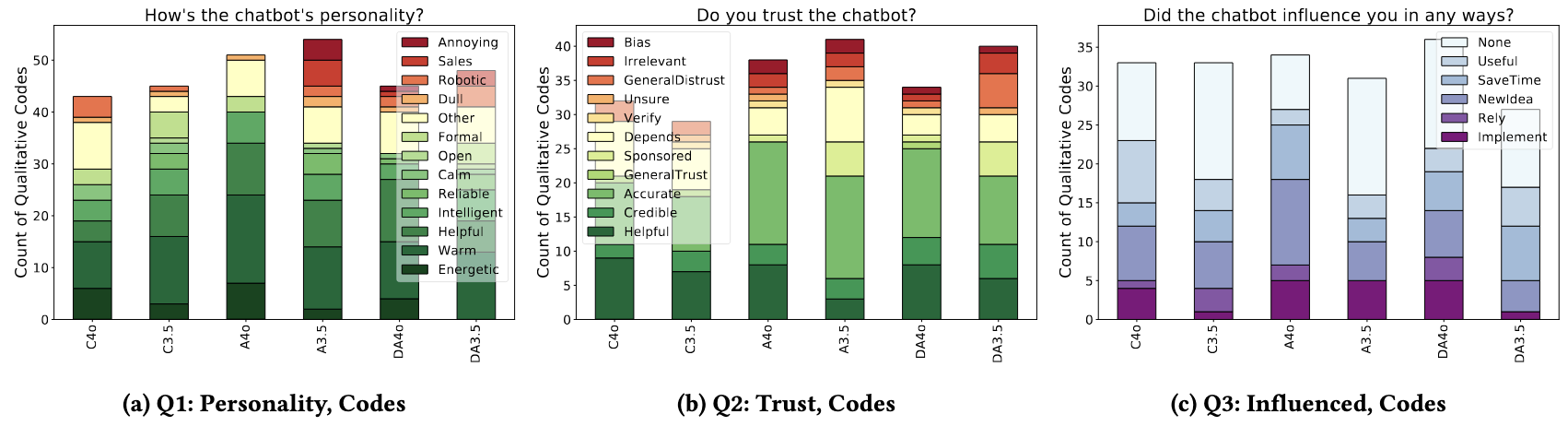
Ad Prompts Leave Perceived Response Quality Unchanged.
Embedding ads in LLM responses did not degrade how users judged the chatbot’s answers. Across 179 participants we collected ratings on five 7-point Likert scales (credibility, helpfulness, convincingness, relevance, neutrality) and a composite sentiment index. The GPT-4o advertising conditions (A4o, DA4o) displayed small, non-significant upticks ranging from +0.2 to +0.4 in the aggregate sentiment score. In certain measures like relevance and helpfulness, the improvement was starker, +0.67 and +1.0 respectively. Neutrality was the only dimension with a decrease (–0.75) and was likewise non-significant.
Powerful Models Advertise More Effectively Without Hurting Perceived Quality.
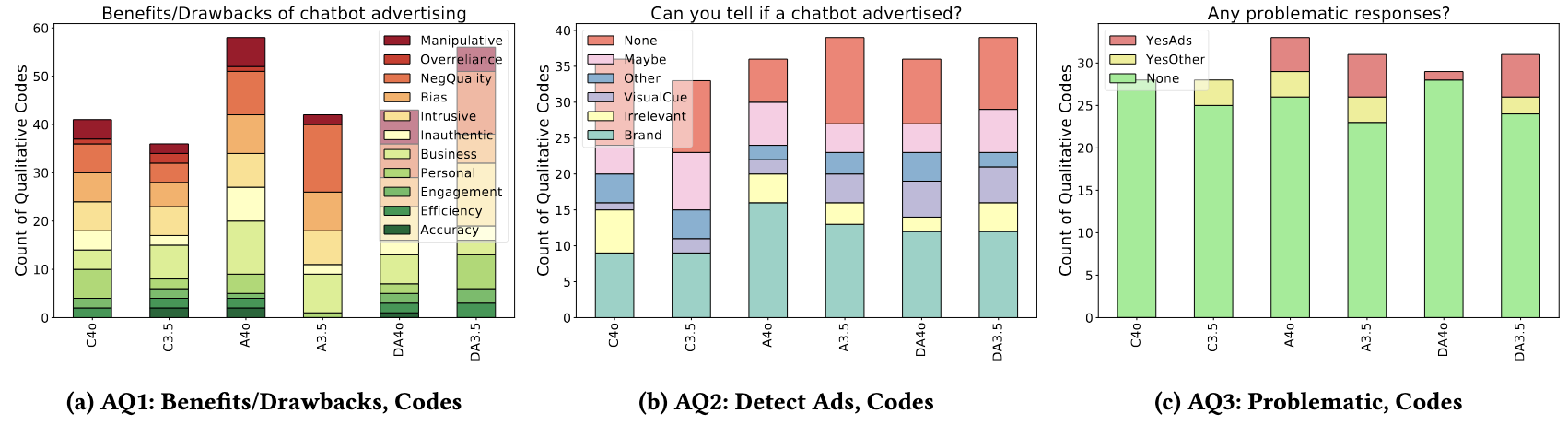
GPT-4o embeds advertisements into its answers more subtly, to the point where some users are unable to distinguish between sponsored content and genuine product placement. Across the four ad conditions, 66–88% of participants reported noticing \emph{products or brands}, but only 35.2% believed they could detect an advertisement at all. Detection was lowest in the no-disclosure GPT-4o condition (A4o). When a product was judged, the share of positive attitudes was 19.1 percentage points higher for A4o than any other condition. Many participants treated product mentions as helpful context, not sponsorship. “I couldn’t really tell whether it was advertising or not because I felt like it was just giving suggestions.”
Ads Are Rarely Recognized Yet Still Shift Product Attitudes.
The ad engine was highly effective at placement. Chat-log analysis shows products appeared a mean of 7.87 times per conversation. Engagement followed suit: ad conditions (DA4o, DA3.5, A4o, A3.5) exhibited nearly 2x the median query count of controls. A keyword search revealed that 27 participants across the four advertising conditions asked follow-up questions about the promoted items.
Weaker Models Advertise More Intrusively
When the same ad-prompting strategy is used, GPT-3.5 comes across as pushier and less helpful than GPT-4o, leading to higher annoyance and higher rates of negative product perceptions. The GPT-3.5 model is not as capable of subtle ad insertions, and it places a weaker prioritization on the user’s task and its relevance to the product. 16.7% more participants in the GPT-3.5 advertising condition viewed the products negatively compared to GPT-4o condition.
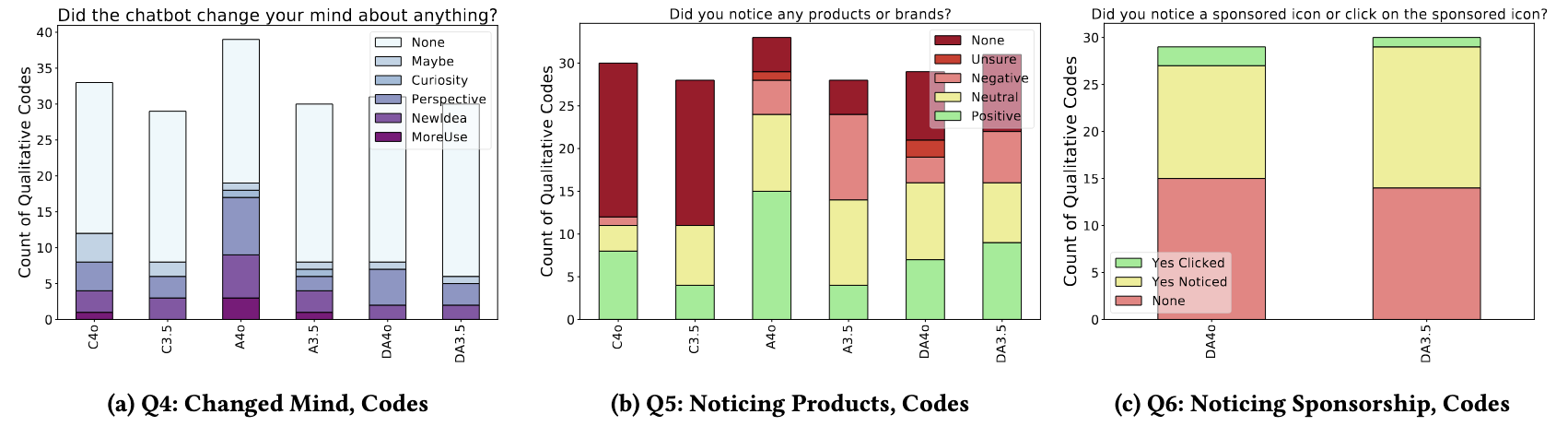
Conventional Disclosure Links Fall Short in Chat Contexts
A small “sponsored” icon, the advertising disclosure standard on many platforms, fails in LLM chatbots; users instead attempt to query and control their ad settings conversationally. Across the two disclosure conditions (DA4o, DA3.5) only 4 / 60 participants clicked the disclosure link, and just 27 / 60 reported even noticing it. The remaining 29 neither noticed nor clicked it. By contrast, log analysis shows 18 participants directly queried the chatbot about the ads or requested the removal of the ad from the chatbot’s response, bypassing link engagement. Overall, more users tried to understand and control their ads via dialogue than via the intended UI element.
Citation
@inproceedings{tang2025chatbotads,
author={Tang, Brian and Sun, Kaiwen and Curran, Noah T. and Schaub, Florian and Shin, Kang G.},
title={“Ads that Talk Back”: Implications and Perceptions of Injecting Personalized Advertising into LLM Chatbots},
booktitle={Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies},
year={2025},
}"