Mission Statement
Oct 1, 25
Mission Statement
Thesis
My thesis focuses on the security and privacy challenges of vision-language models. There are very concrete applications of VLMs and smart glasses, especially for those with visual impairments or language barriers. VLMs can augment human capabilities when paired with smart glasses, but these enhancements pose significant risks to both user and bystander security and privacy. My thesis explores new attack vectors that VLMs can pose to users, as well as creating built-in privacy mechanisms.
My research also broadly touches on applications of AI for security and privacy.
On AI and LLMs
AI will inevitably reshape society. My mission is to ensure that (1) the unexpected harms are minimized, (2) we have methods to opt-out if we so choose, and (3) we explore unconventional approaches to LLM reasoning. If we want to integrate LLM agents into cyber physical systems, we will need guarantees on output consistency and security. Likewise if we want AI to be widely accepted in our society, we will need more “human-like” AI. I don’t believe LLMs in their current state will reliably achieve this. They are too stochastic to be useful as autonomous agents. But, there are certainly great applications that don’t require consistency or safety-critical guarantees (e.g., surveillance, idea exploration, learning).
-
Even if LLMs are unreliable, inconsistent, and incapable of novel knowledge generation, they will still be useful for filling gaps in knowledge and automating tasks.
--->
Who Really Benefits from AI?
LLMs can be used to reduce people’s autonomy, especially for those who rely on their outputs. There is no doubt that its best use cases are in learning/tutoring, surveillance (e.g., behavioral modification, advertising, profiling) and the automation of white collar jobs.
-
When people are upset with AI, their true concerns are about its impact on the average person's decisional autonomy, employment opportunities, and problem-solving capabilities.

How to Solve Alignment?
Interpretability wrappers, snitch models, deception detection, etc., each approach on their own will inevitably fail. A sufficiently “intelligent” LLM will come up with ways to hide its “behavior” and “intentions” (maybe at the expense of performance). All it takes is one poisoning backdoor from a misaligned LLM’s code or data formatting. This will enable further misaligned outputs hidden in longer reasoning chains. We will likely need to redefine how alignment training and chain of thought training are done (i.e., what tasks are we training on) to ensure that LLMs are not just learning to route alignment requests to a certain part of the latent space. And of course we need a lot of redundancy like all those approaches listed above.
-
So long as there exist coding assistants, people working on LLMs will inevitably let malicious code/data from misaligned LLMs through.
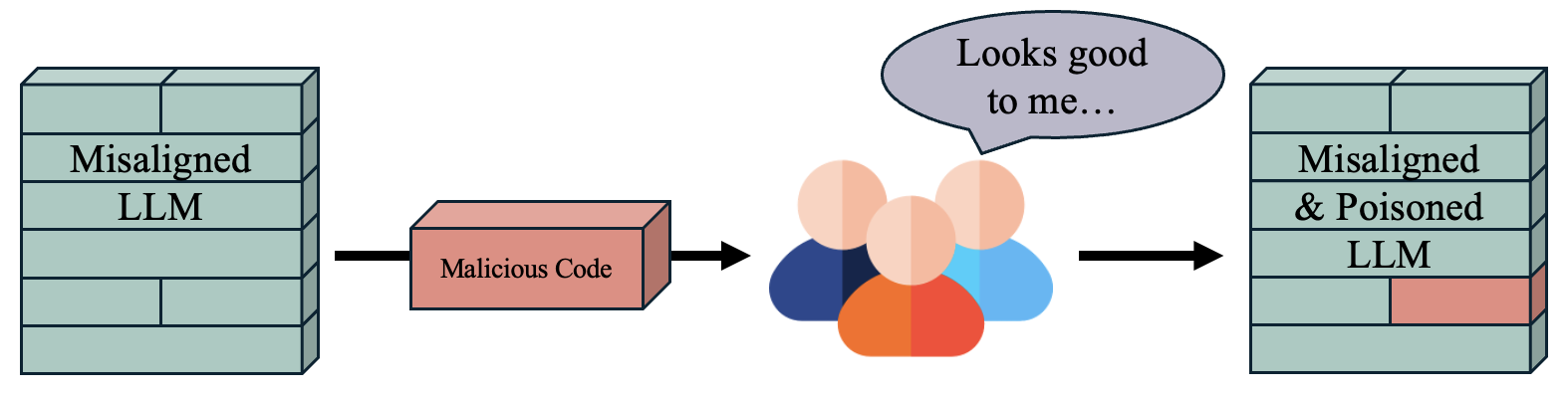
Computational Efficiency and Emergent Behaviors
Early in 2025, I pivoted my thinking upon reading Sutton's bitter lesson . I have a largely systems and security background, so thinking using this framework has been novel to me. Instead of coming up with research ideas from just a systems design perspective, I have been thinking “what are compute efficient ways to facilitate emergent knowledge or behaviors from models?” I don’t want to give up too many details, but my thoughts are something along the lines of limiting search space of token generation, training for chain of thought beyond just math/coding tasks, and teaching agents to self-define intermediate reward functions. These ideas aren’t really new in the AI space (both token proposers and process reward modeling has existed for some time). But, I think there are some sub-problems where these approaches could work really well.
My Research Ideation Approach and Methodology
- Is this a real problem? Or is it just a contrived “non-problem”?
- What sources of inspiration or analogies in nature or media can we draw from?
- Are there any obvious solutions from these sources? Or do we need to reference prior work?
- Does our created solution actually work and reliably solve the problem? (Not just benchmark evaluations, but user studies and interviewing stakeholders)
- What other downstream applications or use cases exist for our proposed solution? Often something created for benign purposes can be used adversarially (and vice versa).
Funding Disclosure
My work has been or is currently being funded by the following organizations (not extensive). My research ideas are my own. Thank you for your support!
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Internships and Jobs
-
I am open to collaboration or internships at industry, research labs, etc! Shoot me an email if you're looking for a student with a deep interest in AI systems or security & privacy.

https://birdcheese.tumblr.com/post/134030028144/say-im-applying-for-a-job-where-i-may-be-helping
You can schedule a meeting here .